在操作系统的搭建的内核线程之上,go 语言搭建了一个特有的两极线程模型。首先来了解一下线程实现模型,然后再详细了解 go 语言实现的
线程实现模型
线程的实现模型主要有三种:用户级线程模型、内核级线程模型、两极线程模型。它们之间的区别主要是线程与内核调度对象之间的的对应关系。内核调度象也就是内核线程。
用户级线程模型
用户级线程模型是由用户级别的线程库来全权管理的。也就是说,用户级线程模型下的线程是往往是通过应用程序的线程库来创建、切换、销毁的。与操作系统内核的线程没有关系。操作系统内核的线程调度器也无法
调度用户级线程模型创建的线程。内核线程调度器只能调度创建此线程的的应用程序的进程。一个进程对应多个用户级线程,所以这种线程模型又称为多对一(M:1)的线程模型, 如下图所示: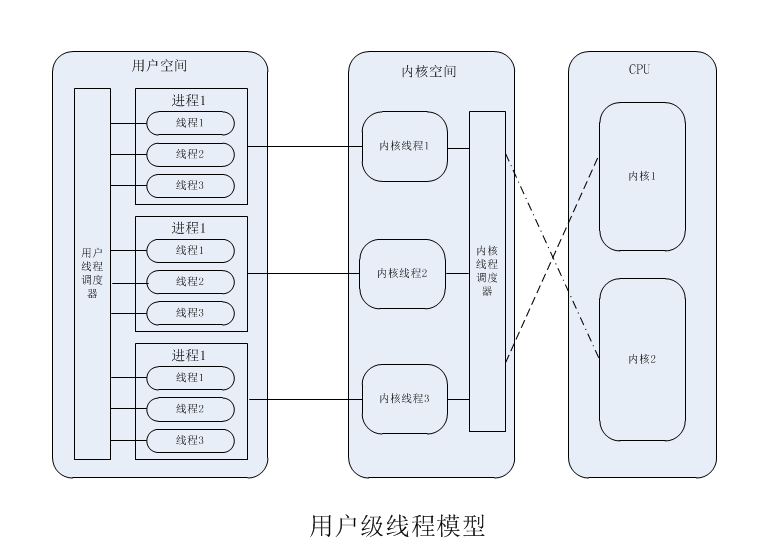
优势
- 对线程的各种管理调度与内核无关。应用程序对线程的创建、终止、切换等操作不需要让CPU从用户态切换到内核态。速度方面比较有优势
- 由于不依赖内核,所以程序的一致性比较强
劣势
- 由于此模型下内核调度的最小单位是进程。如果线程阻塞,则整个进程被阻塞。
- 不能真正利用多核 CPU 来实现并发。进程中的多个线程无法被分配到多个 CPU 中去执行。
综上所述,由于缺陷明显,所以现在的操作系统一般不使用此种模型来实现线程
内核级线程模型
和用户级线程相反,内核级线程是由内核来管理的,属于内核的一部分。应用程序对线程的创建、终止、切换等操作必须通过内核提供的系统调用来完成。进程中的每一个线程都与内核线程一一对应
由此,也称为一对一(1:1)的线程模型。如下图所示:
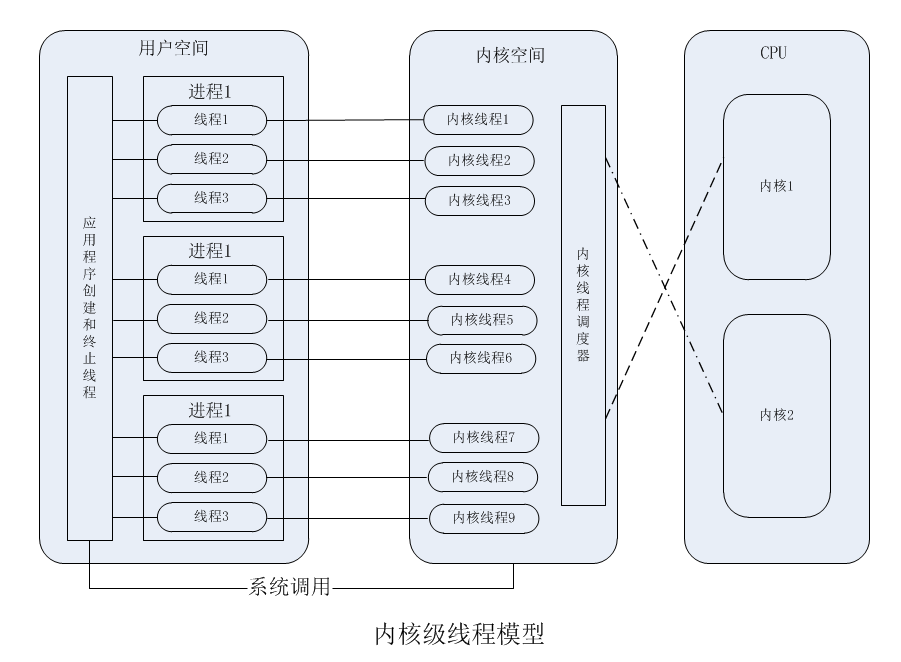
优势
- 一对一的线程模型消除了多对一的线程模型的不能真正并发的弊端,线程的管理由内核管理和调度,内核可以在不同的时间片内让CPU运行不同的线程。
- 即使某一个线程收到阻塞,其他线程不受影响
劣势
- 创建线程和管理线程的成本加大,要经常去系统调用来管理线程,线程管理的时间耗费的时间相对比较大。
- 如果一个进程包含大量的线程,将会给内核的调度器带来非常大的负担,甚至会影响操作系统的整体性能。
- 消耗更多的内核资源
尽管内核级线程也有劣势,但是相比用户级线程的优势还是比较明显的。很多的现代的操作系统都是以内核级线程模型来实现线程的。包括 Linux 操作系统。
需要注意的是,在使用内核级线程模型时,必须了解每个进程允许的线程的最大数目是多少。防止线程数过大造成操作系统性能下降甚至崩溃。
两极线程模型
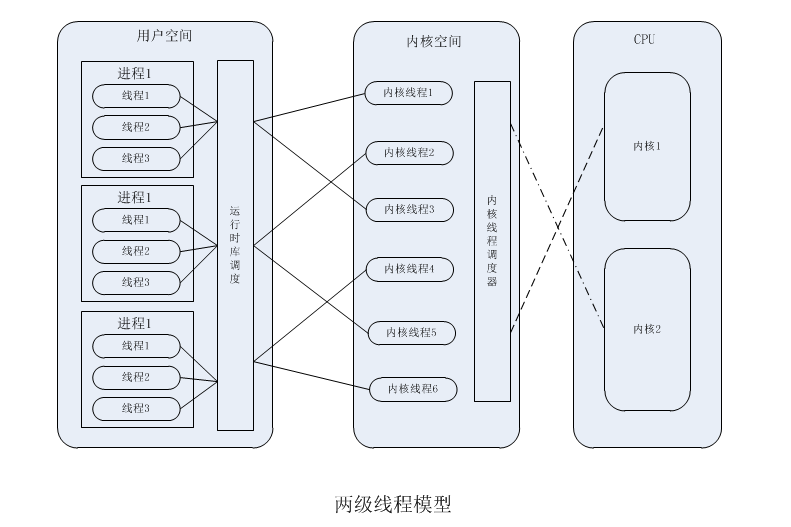
两极线程模型是根据用户级线程模型和内核级线程模型综合演变而来。可以说是取前两种模型之精华,去前两种模型之糟粕。在此模型下,一个进程可以与多个内核线程相关联。这与内核级线程相似。但与内核线程模型
不同的是,进程中的线程并不与内核线程一一对应,这些应用程序线程可以映射到同一个已关联的内核线程上。
首先实现了两极线程模型的线程库会通过操作系统调用创建多个内核线程。然后,它会通过这些内核线程对应用程序线程进行调度。大多数的此类线程库都可以将这些应用程序线程动态的与内核线程相关联。在这种实现中,进程有着自己的内核线程池。可运行的用户线程由运行时库分派并标记为准备好执行的可用线程。
操作系统选择用户线程并将它映射到线程池中的可用内核线程。多个用户线程可以分配给相同的内核线程。
如下图所示:
优势
- 内核资源的消耗大大减少
- 线程管理操作的效率提高
劣势
- 由于此种模型的线程设计使得管理工作变得更加复杂
因为两极线程的复杂性,往往不会被操作系统所采用,但是,这样的模型却可以很好地在编程语言层面上实现并充分发挥作用。Go 语言的并发模型正是在该模型的基础上实现的。
Go 语言并发模型
Go 的线程实现模型。有三个必知的核心元素。他们支撑起了模型的主要框架。
- M (machine)一个 M 代表一个内核线程
- P (processor)一个 P 代表一个 Go 代码片段所必须的资源。goroutine依赖于 P 进行调度,P 是真正的并行单元;
- G (goroutine)一个 G 代表一个 Go 代码片段。
简单来说,一个 G 的执行,需要 P 和 M 的支持。一个 M 在一个 P 关联之后就形成了一个有效的 G 的运行环境(内核线程 + 上下文环境)。
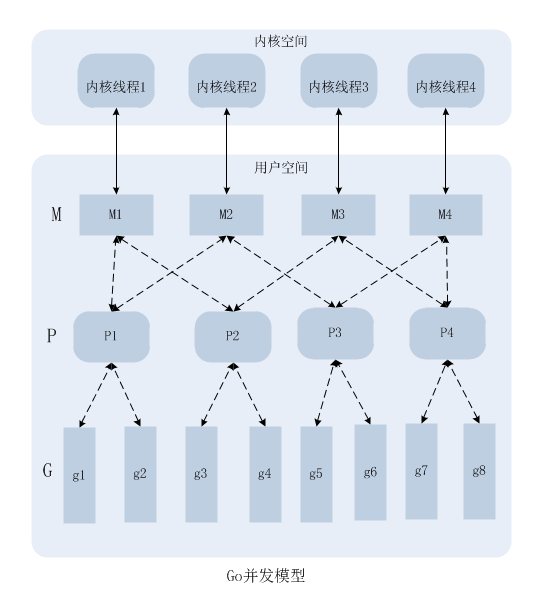
对应关系:
- M 与操作系统内核线程是一对一的关系。即一个 M 只能代表一个内核级线程。并且他们之间的关系一旦关联一般不可改变。
- M 与 P 之间的关系也是一对一的关系。但是他们之间的关联是易变的。会根据实际的调度来确定哪个 P 和 M 关联。
- P 与 G 之间的关系是一对多的关系。因为每个 P 中都有一个可运行的 G 队列。
M
上面已经讲了,一个 M 代表一个内核线程。一般情况下,创建 M 的时机一般是由于没有足够的 M 来管理 P ,并运行 P 中的可执行队列中的 G 。除此之外,在运行时系统执行监控和垃圾回收的过程中
也会导致新的 M 的创建。
M 的核心结构字段
1 | type M struct { |
M 的生命周期
- 创建 M,M 在创建后加入全局的 M 列表中。起始函数和预关联的 P 都会被设置好。
- 运行时系统会为 M 专门创建一个新的内核线程并与之相关联。
- 初始化 M (栈空间,信号等)
- 开始执行起始函数(如果存在的话)
- 起始函数执行完成后,当前 M 会与预关联的 P 完成关联,并准备执行其他任务。M 会依次在多处寻找可运行的 G 。
单个 Go 程序的 M 的最大值是可以设置的,初始化调度器的时候,会对 M 最大数量初始化。最大值为 10000。也就是说最多有 10000 个内核级线程服务于当前的 Go。但是在真正的操作系统运行环境中,基本上很难达到如此的量级的线程共存。
所以可以忽略 Go 本身对于线程数量的限制。也可以通过标准库代码包 runtime/debug 中的 SetMaxThreads 函数来限制 M 的最大值。
P
P 是 G 能够在 M 中运行的桥梁,Go 的运行时系统会适时的让 P 与不同的 M 建立或断开连接,使得 P 中的那些 G 能够及时获得运行时机,就像是操作系统内核在 CPU 之上的适时切换不同的进程和线程的场景类似
改变 P 的最大数量有两种方法:
- 调用函数 runtime.GOMAXPROCS 传入参数的方式
- 在 Go 程序运行前设置环境变量 GOMAXPROCS 的值
P 的最大值是 Go 程序并发规模的的限制。P 的数量即可运行的 G 的队列的数量。一个 G 被启动后,首先会被追加到某个 P 中的可运行 G 队列中,等待时机运行。
在设置 P 的最大值的时候,会检查该值的有效性,当前,Go 目前还不能保证在数量比 256 更多的 P 同时存在的情形下 Go 仍能保持高效,因此,只要不大于 256,都是被认为是有效的值。
一般情况下,P 设置为当前计算机的 CPU 核数。
G
每个 G 代表一个 goroutine, 编程时,我们使用 go 语句只是提交了一个并发任务。而 Go 的运行时系统则会安装要求并发执行它。那么当执行 go 关键字的时候发生了什么呢?
Go 编译器会把 go 语句变成对内部函数 newproc (runtime.proc.go) 的调用。
1 | func newproc(siz int32, fn *funcval) { |
真正执行的函数在 newproc1(), 有需要请自行看源码,执行顺序如下:
- 获得当前的 G 所在的 P,然后从空闲的 G 队列中取出一个 G
- 如果 1 取到则对这个 G 进行参数配置,否则新建一个G
- 将 G 加入 P 的可运行的 G 队列
调度器
在 Go 语言中,调度器的主要调度对象就是 M, P, G 的实例。调度器在调度过程中需要依赖全局的调度对象的容器。简单来说,为了方便调度,调度器会对 M,P,G 的实例存储在容器中。
调度器的容器包括:
- 调度器的空闲 M 列表:存放空闲的 M 的单向链表
- 调度器的空闲 P 列表:存放空闲的 P 的单向链表
- 调度器的可运行 G 队列:存放可运行 G 的队列
- 调度器的自由 G 列表:存放自由的 G 的单向链表
调度器有自己的数据结构,形成此结构的主要目的是更加方便的管理和调度各个核心元素的实例。
基本结构
goroutine
goroutine 的核心理念是:
1 | 不要以共享内存的方式来通信。应该以通信作为手段来共享内存 |