Mysql 数据库是目前最流行使用最广泛的关系型数据库,通过本系列来复习一下 Mysql 索引相关的知识。
本篇文章来讲解一下索引的具体实现。
为什么要使用索引
1 | 什么是索引?为什么要使用索引? |
索引就是存储引擎用于快速找到记录的一种数据结构。把数据库比做一本书,如果查找内容就需要每一页每一页的找,那岂不是效率很低。
那么我们设计了一套规则:
- 将书分按照一章一章的分类,每一章又分为不同的小章节
- 将分好的章节信息保存在目录页里
每次查询的时候我们先查找目录,找到目标的章节,最后一直找到想要找到的内容。
通俗来说,索引的设计就是用来加快数据库的访问速度。
索引的实现方式
通常为了加快数据的速度,一般两种数据结构来实现:
- Hash 哈希
- Tree 树
Hash 结构
通过 Hash 函数将数据映射到哈希桶里,哈希桶是顺序存储的数据结构,所以插入/更新/删除数据时,可以直接找到数据的位置,时间复杂度是 O(1)。可以说是非常快速
Mysql 的 memory 存储引擎使用的就是哈希索引。
Tree 结构
二叉搜索树
二叉搜索树是我们最熟悉页最常见的树结构,如下图所示:
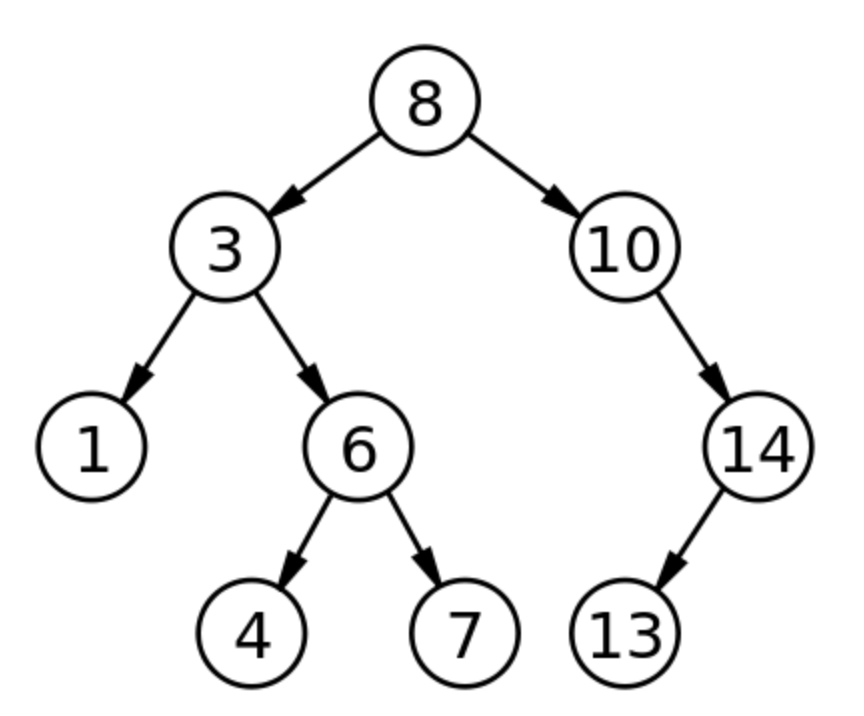
我们看到,由于二叉搜索树是二叉的,所以当数据量很大的时候,存在以下问题:
- 树的高度比较高
- 每个节点只能存储一条记录,每次查询到该节点都要进行磁盘 I/O
二叉搜索树的查找时间复杂度是 O(logn)
B 树
为了适用数据库的查找,发明了 B 树的数据结构,实际上是一种多路搜索树,如下图所示:
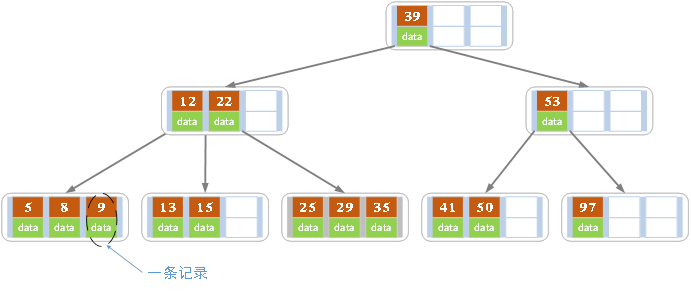
B 树的特点是:
- 不再是二叉,而是多叉
- 叶子节点和非叶子节点都存储数据
- 每个非根节点可以存储多条记录,个数满足 (m/2 - 1) <= j <= m-1
- 中序遍历可以获取所有节点
可以发现,B 树相对于二叉搜索树,高度大大降低,并且每个非叶子节点可以存储多条记录,这样做有什么好处?
这是因为这样做,可以利用局部性原理来降低磁盘 I/O,提高读取效率。
这里简单解释一下局部性原理。
局部性原理
- 磁盘的读取相对内存来说要慢很多,所以应尽量减少磁盘的读取操作。
- 磁盘预读,磁盘一次读取,并不会按需读取,而是按页读取,一次读一页,如果以后要读的数据就在这一页中,就可以避免再次读取磁盘,提高效率。
- 软件或程序设计过程中应该尽量遵循这样的原则,例如,对于 B 树的非叶子节点来说,每个节点可以设置为一页的数据,只需读取一次即可。
通常,磁盘读取一页的数据是 4k
B 树一般被用来设计做数据库的索引的优势:
- 多叉搜索树,高度降低。
- 每个节点存储多个记录,利用局部性原理,降低了磁盘读取次数,提高了读取效率
1 | 哈希索引更快更简单,数据库为什么不使用哈希索引? |
哈希索引是更快,但是哈希索引对于 分组(group by)排序(order by)以及范围查找(> <)需要全表扫描才行,时间复杂读退化为 O(n)
Mysql Innodb 索引的实现
Mysql Innodb 存储引擎的索引使用的是在 B 树上优化的一种数据结构,B+ 树。
B+ 树也是多路搜索树,是在 B 树的基础上优化而来,如下图所示:
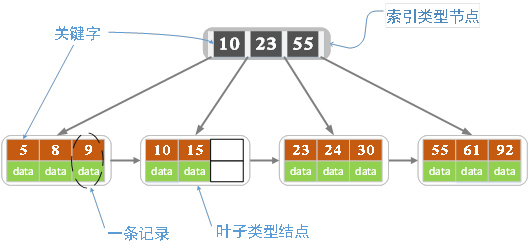
B+ 树具备 B 树的优点,同时又做了以下优化:
- 非叶子节点上不再存储数据,只记录记录的key,只有叶子节点上才存储数据记录
- 所有的叶子节点,都通过链表连接起来,方便了范围查找
优化的好处:
- 非叶子节点不存数据,只记录 key,相同内存下,B+树存储更多的索引
- 增加的链表,方便了范围查找。
聚集索引和非聚集索引
聚集索引和非聚集索引并不是索引类型,只是存储方式不同而已;这里简单介绍下聚集索引和非聚集索引的区别。
聚集索引
聚集索引就是索引和数据记录存储在一起的索引,例如在上面说的 B+树的数据结构中,叶子节点最终保存的不仅是索引的 key ,还包括索引的数据。InnoDB 就是使用的聚集索引,如下图就是 InnoDB 的主键索引的存储结构:
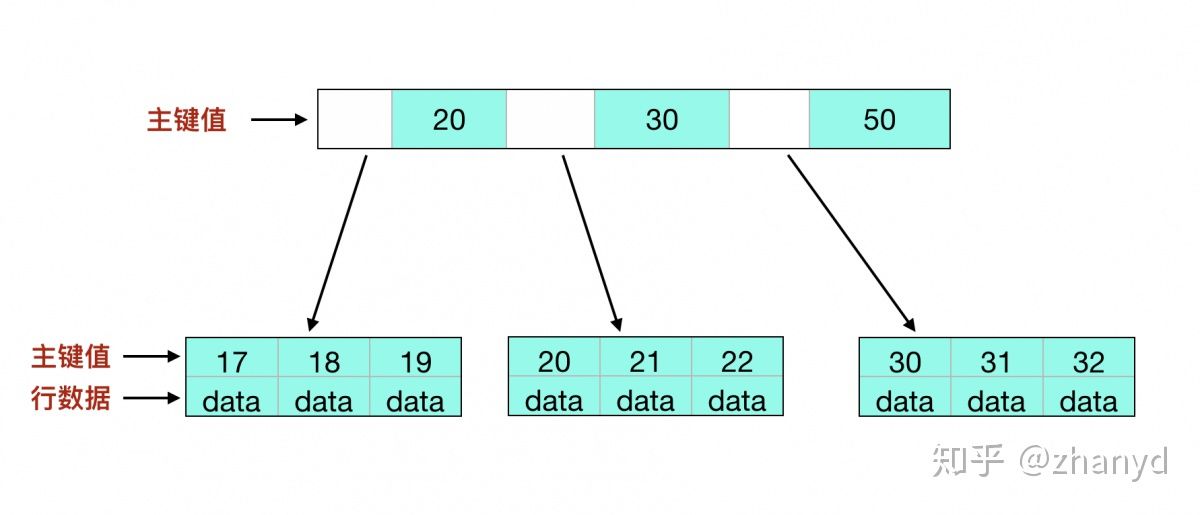
可以看到叶子节点上本身就存在数据,所以通过索引查找可以直接查找到数据。
聚集索引的好处:
- 可以把数据保存在一起。只需要从磁盘读取少数的数据也就能获取数据。
- 数据访问更快。
- 使用覆盖索引扫描的查询可以直接使用节点的主键值
非聚集索引
和聚集索引相反,非聚集索引就是数据和索引分开存储的索引。MyISAM 使用的就是非聚集索引
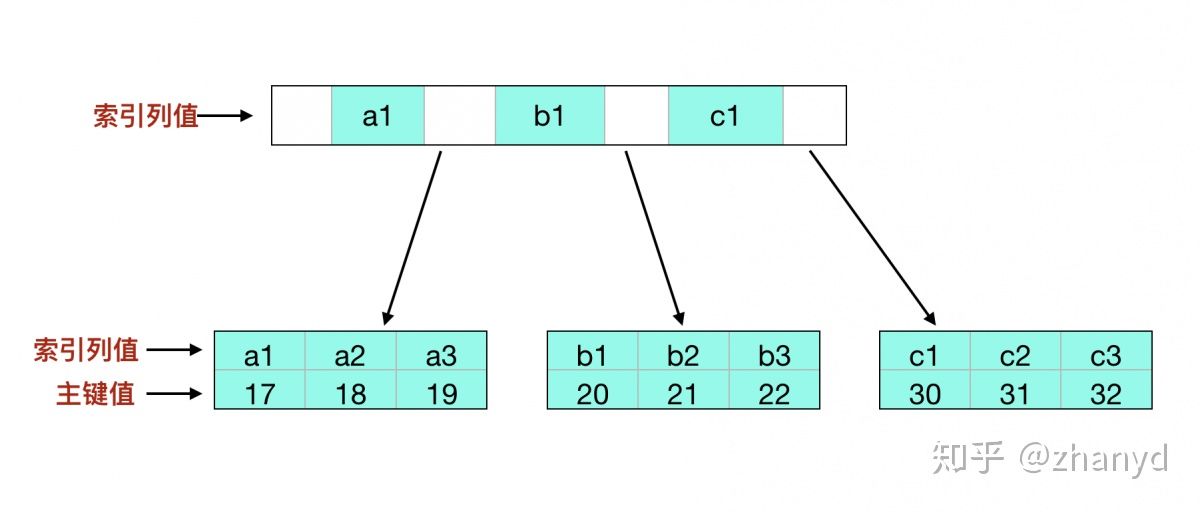
可以看到,叶子节点存储的的是索引的 key 和 行号, 行号即索引数据在数据文件的位置。
二级索引
对于 InnoDB 来说,主键索引是聚集索引,但是二级索引(辅助索引)和聚集索引很不相同。InnoDB 二级索引的叶子节点存储的是主键值,所以,二级索引查找可能需要查找两次,首先根据索引查找到数据的主键值,然后再根据主键从主键索引查到数据。
所以,从这一点来看,我们就明白了 InnoDB 必须存在主键,如果没有显示的主键,InnoDB 会先查找非空的唯一索引当主键,否则会自己生成一个隐藏的主键。
对于 MyISAM 来说,二级索引和主键索引的实现方式一样。
总结
只有了解了索引的底层实现,才能更好的使用索引和优化索引。