上一篇文章介绍了 Redis 集群的主从同步模式,虽然配置简单,但是缺点也十分突出:Master 内存受限,Master 宕机之后不能自动切换,不能水平扩容等等。本篇文章来介绍 Redis 的第二种集群模式 哨兵模式
什么是哨兵模式(Redis Sentinel)
哨兵(Sentinel)模式下会启动多个哨兵进程,哨兵进程的作用如下:
- 监控:能持续的监控 Redis 集群中主从节点的工作状态
- 通知:当被监控的节点出现问题之后,能通过 API 来通知系统管理员或其他程序
- 自动故障处理:如果发现主节点无法正常工作,哨兵进程将启动故障恢复机制把一个从节点提升为主节点,其他的从节点将会重新配置到新的主节点,并且应用程序会得到一个更换新地址的通知
哨兵模式的应用场景
当采用 Master-Slave 的高可用方案时候,如果 Master 宕机之后,想自动切换,可以考虑使用哨兵模式。哨兵模式其实是在主从模式的基础上工作的。
哨兵模式搭建
版本
Redis-3.2
环境
- windows: Master 192.168.238.1:6379
- linux: Slave1 192.168.238.129:6380
- linux: Slave2 192.168.238.129:6381
配置
主从配置
这里不再多说,参考上一篇文章 Redis系列(一):Redis 主从同步集群模式
哨兵配置
三个节点配置一样的哨兵文件 sentinel.conf1
2
3
4
5
6
7
8
9
10#当前Sentinel服务运行的端口
port 26379
# 哨兵监听的主服务器
sentinel monitor mymaster 192.168.238.1 6379 2
# 3s 内mymaster无响应,则认为mymaster宕机了
sentinel down-after-milliseconds mymaster 3000
#如果 10 秒后, mysater仍没启动过来,则启动 failover
sentinel failover-timeout mymaster 10000
# 执行故障转移时, 最多有1个从服务器同时对新的主服务器进行同步
sentinel parallel-syncs mymaster 1
Slave1 和 Slave2 由于在同一台机器上,所以需要修改一下 sentinel.conf 哨兵进程的端口,其他配置不变
Slave1
1
port 26380
Slave2
1
port 26381
启动哨兵
Master: 192.168.238.1:6379
1
2
3> redis-server.exe sentinel.conf --sentinel
[9080] 11 Oct 10:36:57.649 # Sentinel runid is 0ccfa091a43d8c8d11cec3aa606395f0400d5499
[9080] 11 Oct 10:36:57.650 # +monitor master mymaster 192.168.238.1 6379 quorum 2Slave1: 192.168.238.129:6380
1
2
3
4
5> /usr/local/redis/bin/redis-sentinel /usr/local/redis/etc/sentinel_6380.conf
8128:X 11 Oct 10:35:42.843 # Sentinel ID is 9e3c5ef3ec6f595ae273d52ff5ee8f5badf9729a
8128:X 11 Oct 10:35:42.844 # +monitor master mymaster 192.168.238.1 6379 quorum 2
8128:X 11 Oct 10:35:42.854 * +slave slave 192.168.238.129:6380 192.168.238.129 6380 @ mymaster 192.168.238.1 6379
8128:X 11 Oct 10:35:42.861 * +slave slave 192.168.238.129:6381 192.168.238.129 6381 @ mymaster 192.168.238.1 6379Slave2: 192.168.238.129:6381
1
2
3
4
5
6
7> /usr/local/redis/bin/redis-sentinel /usr/local/redis/etc/sentinel_6381.conf
8135:X 11 Oct 10:36:03.296 # Sentinel ID is c2c03e1548ca7ecd53ff8191dcf681fea8f95ba5
8135:X 11 Oct 10:36:03.296 # +monitor master mymaster 192.168.238.1 6379 quorum 2
8135:X 11 Oct 10:36:03.303 * +slave slave 192.168.238.129:6380 192.168.238.129 6380 @ mymaster 192.168.238.1 6379
8135:X 11 Oct 10:36:03.311 * +slave slave 192.168.238.129:6381 192.168.238.129 6381 @ mymaster 192.168.238.1 6379
8135:X 11 Oct 10:36:03.353 * +sentinel sentinel 9e3c5ef3ec6f595ae273d52ff5ee8f5badf9729a 192.168.238.129 26380 @ mymaster 192.168.238.1 6379
8135:X 11 Oct 10:36:57.782 * +sentinel sentinel 0ccfa091a43d8c8d11cec3aa606395f0400d5499 192.168.238.1 26379 @ mymaster 192.168.238.1 6379查看一下主节点的主从配置
1
2
3
4
5
6127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.238.129,port=6380,state=online,offset=70740,lag=1
slave1:ip=192.168.238.129,port=6381,state=online,offset=70740,lag=0
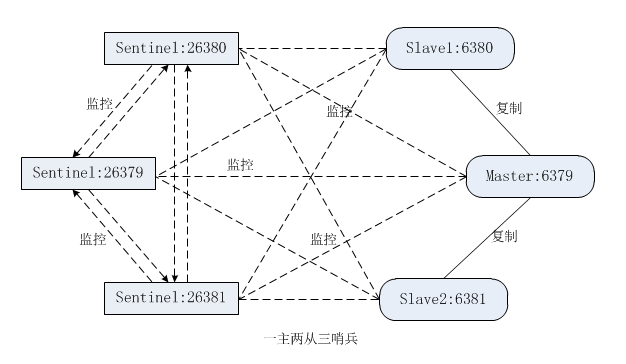
至此 一主两从三哨兵 的集群模式已搭建成功
测试
主从同步测试
- Master
1
2
3> redis-cli.exe
127.0.0.1:6379> set "foo" bar1
OK Slave1
1
2
3> ./redis-cli -p 6380
127.0.0.1:6380> get foo
"bar1"Slave2
1
2
3> ./redis-cli -p 6381
127.0.0.1:6381> get foo
"bar1"主从切换测试
Master 节点宕机
观察 Slave1 节点的 sentinel 进程的输出日志:1
2
3
4
58128:X 11 Oct 10:38:11.306 # +config-update-from sentinel 0ccfa091a43d8c8d11cec3aa606395f0400d5499 192.168.238.1 26379 @ mymaster 192.168.238.1 6379
8128:X 11 Oct 10:38:11.306 # +switch-master mymaster 192.168.238.1 6379 192.168.238.129 6380
8128:X 11 Oct 10:38:11.306 * +slave slave 192.168.238.129:6381 192.168.238.129 6381 @ mymaster 192.168.238.129 6380
8128:X 11 Oct 10:38:11.306 * +slave slave 192.168.238.1:6379 192.168.238.1 6379 @ mymaster 192.168.238.129 6380
8128:X 11 Oct 10:38:14.381 # +sdown slave 192.168.238.1:6379 192.168.238.1 6379 @ mymaster 192.168.238.129 6380
Slave 的哨兵进程发现 Master 出现问题,然后选举 Slave2 为 Master 节点( @ mymaster 192.168.238.129 6380), 原 Master 节点 192.168.238.1:6379 降为 Slave 节点
这时我们查看一下 Slave2 的主从配置
1 | 127.0.0.1:6380> info replication |
很明显,6380 的 redis 实例称为了 master 节点。主从自动切换成功
- Master 节点到宕机之后恢复
当 6379 的 Redis 实例重新恢复运行时,原来的 Master 自动切换成 Slave,不会自动恢复成 Master。
- Slave 节点宕机
使 Slave1(6380) 节点 shutdown, 模拟宕机,观察 master 节点 6379 的 info replication 信息我们发现 6389 的 slave 结点不见了。1
2
3
4
5127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave1:ip=192.168.238.129,port=6381,state=online,offset=70740,lag=0
重新启动 slave1 节点。master 节点的同步从节点又会变成两个。
哨兵进程的工作方式
- 每个哨兵进程会以每秒钟一次的频率向整个集群中的
Master 结点、Slave 节点、Sentinel 进程发送一个 PING 命令 - 如果一个实例距离最后一次有效回复 PING 命令的时间超过
down-after-milliseconds选项所指定的值,则这个实例就会被哨兵进程标记为主观下线 - 如果一个 Master 节点被标记为
主观下线,则所有监视这个 Master 节点的哨兵进程都需要以每秒一次的频率确认 Master 主服务器的确进入了主观下线状态 - 当有足够数量的哨兵进程在指定时间范围内确认了 Master 主节点进入了
主观下线状态,则 Master 节点就会被标记为客观下线 - 每个哨兵进程会以每 10 秒一次的频率向集群中的所有 Master/Slave 机器发送 INFO 命令,并从回复信息中提取从节点ID、从节点角色、从节点所属的主节点的ip及端口、主从节点的连接状态、从节点的优先级、从节点的复制偏移量等信息;
- 若没有足够数量的哨兵进程同意 Master 主节点下线,Master 主节点的客观下线状态就会被移除。若 Master 主节点重新向哨兵进程发送 PING 返回有效的回复, Master 主节点的主观下线状态就会被移除
主观下线
所谓主观下线就是单个的哨兵进程认为某个服务下线,带有主观意识。
标记为主观下线,是根据发送的 PING 命令是否有效回复来判断,当然主观下线的时间长度可以设置,down-after-milliseconds 毫秒内返回的都是无效回复,则标记为主观下线。
客观下线
所谓的客观下线,就是当一个哨兵进程标记某个服务为主观下线时,哨兵需要询问其他的哨兵进程是否也认为该服务为主观下线,接受到足够数量的主观下线的时候,那么该服务就被认为是客观下线。然后开始对服务进行故障转移工作。
领头哨兵的选举
如果一个 Redis 节点被标记为客观下线,那么所有监控改服务的哨兵进程会进行协商,选举出一个领头的哨兵,对 Redis 服务进行转移故障操作。领头哨兵的选举大概遵循以下原则:
- 所有的哨兵都有公平的机会被选举为领头哨兵
- 在一轮选举中,所有的哨兵都有且仅有一次机会被选举称领头哨兵,一旦选举,不可更改
- 如果某个哨兵被半数以上的哨兵设置为领头,那么该哨兵称为领头哨兵
- 如果在限定时间内没选举出来,那么暂停一段时间,再次选举
故障转移
哨兵模式最大的优点即可以进行故障转移,提高了服务的高可用。故障转移分为三个步骤:
从下线的主节点所有的从节点中挑选一个从节点,将其转成主节点
选举出来的领头哨兵从列表中选择优先级最高的,如果优先级都一样,则选择偏移量大的(偏移量大说明数据比较新),如果偏移量一样,则选择运行ID比较小的将已下线的主节点的所有从节点改为向新的主节点进行复制
挑选出来了新的主节点服务之后,领头哨兵会向原主节点的所有从节点发送 slaveof 新主节点的命令,复制新的 Master当已下线的原主节点恢复服务时,复制新的主节点,变成新主节点的从节点
当已下线的服务重新上线时,sentinel会向其发送 slaveof 命令,让其成为新主节点的从节点
哨兵模式优缺点
优点
- 哨兵模式本身就是基于主从模式,所以具有主从同步模式的优点
- 主从可以切换,故障转移,提高系统的可用性
- 系统更加健壮稳定
缺点
当 Redis 集群容量达到一定程度时,不能很好的支持在线扩容,所以在使用前必须确保有足够的空间。
总结
可以说,哨兵模式是对主从同步模式的一个补充,使得 Redis 集群更加的稳健,可用性更高。但是该种模式下的 Redis 不能水平扩容,不能随时增加或删除结点,这也限制了哨兵模式的广泛使用。在 Redis3.0
之后的版本提供了更加强大的集群模式,Cluster 集群模式,下一篇文章我们再详细讨论。