http1.1 是当前 web 应用使用的主流的 http 协议版本,http1.1 在 http1.0 的基础上做了一些的优化,我们看看具体的区别有哪些。
http/1.0
- 多格式文件支持,这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。
- 多请求方式支持,除了GET命令,还引入了POST命令和HEAD命令。
- HTTP请求和回应的格式也变了。除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
- 其他的新增功能还包括状态码(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
缺点:
- 每个TCP连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
- TCP连接的新建成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)
http/1.1
- 引入了持久连接(persistent connection),即TCP连接默认不关闭,可以被多个请求复用,不用声明Connection: keep-alive,使用connection: close关闭TCP连接
- 引入了管道机制(pipelining),即在同一个TCP连接里面,客户端可以同时发送多个请求。这样就进一步改进了HTTP协议的效率。但是服务器还是要按照顺序来回应请求。
- 可以使用分块传输编码。
- 新增了许多动词方法:PUT、PATCH、 OPTIONS、DELETE。
- 客户端请求的头信息新增了 Host 字段,用来指定服务器的域名。
缺点:
虽然1.1版允许复用TCP连接,但是同一个TCP连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个回应,才会进行下一个回应。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为 ”队头堵塞“。
为了避免这个问题,只有两种方法:一是减少请求数,二是同时多开持久连接。
http1.0 串行连接
早期的 http 协议对于每一个单独的请求都独占一个 tcp 连接,并且请求处理都是串行化的。例如有三个 css 文件需要加载,同属于一个协议、域名、端口。那浏览器需要顺序的发起 4 个请求,每次都需要重新打开一个 tcp 的通道,在请求资源完成后断开连接,再开启下一个新的连接去处理队列中的请求。显然当资源数量越来越大,页面发起的请求越来越多情况下,页面加载时间会过长,页面白的几率越高。
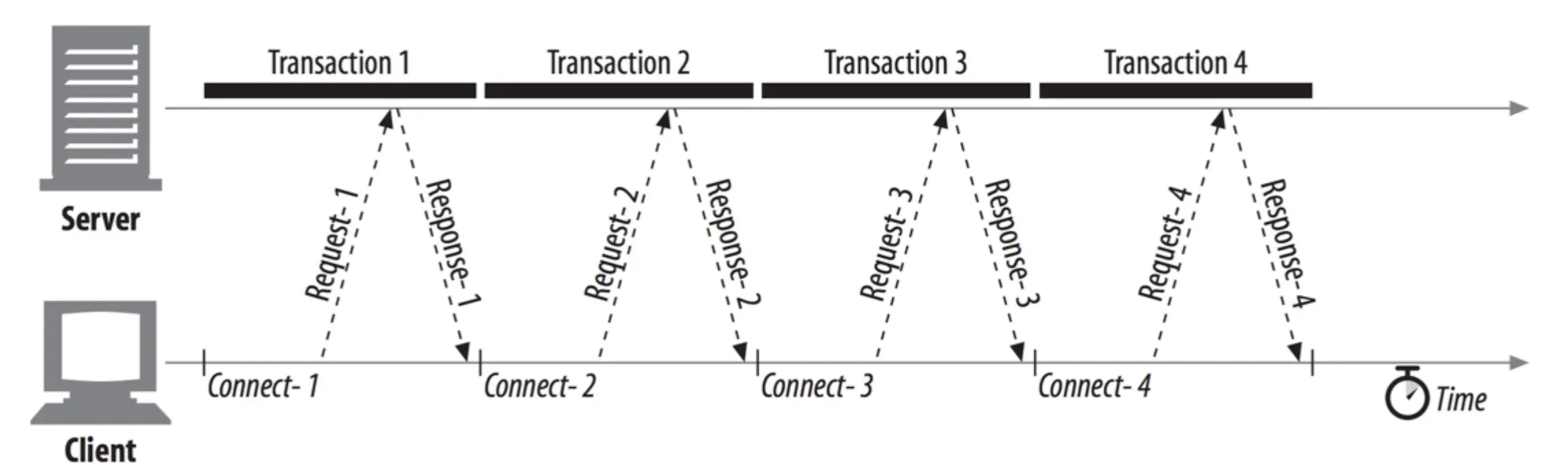
并行连接
为了提高网络的吞吐能力,改进后的 http 协议允许客户端同时打开多个 TCP 连接,并行的去请求多个资源,充分利用带宽。请求的传输时间是重叠的,单总体比串行连接低很多。考虑到每一个连接都会消耗系统资源,并且服务器需要处理海量的用户并发请求,浏览器会对并发请求数量做一定的限制。一般浏览器的限制是 6 个。
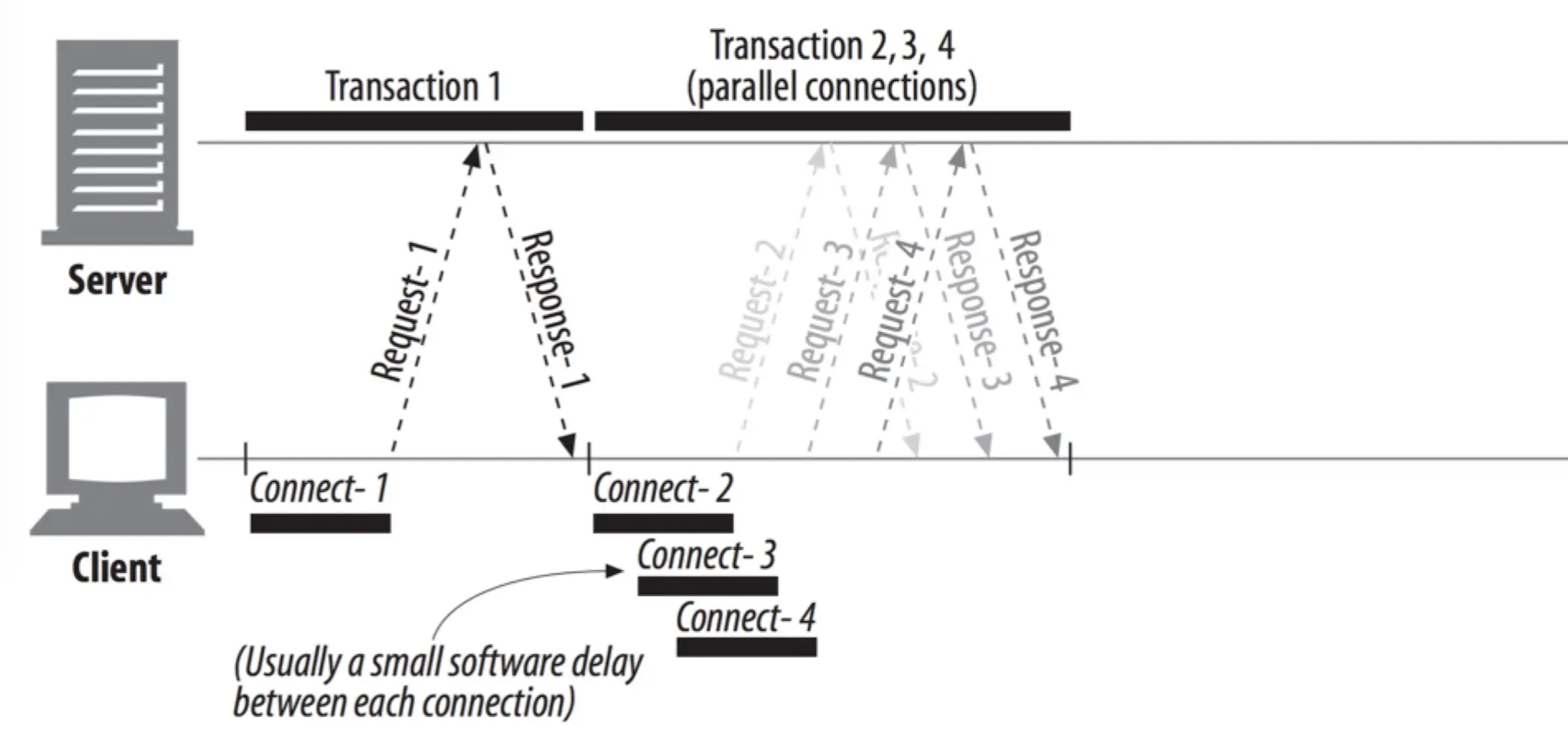
http1.1 keep-alive 连接
通过一个图示来说明,详细描述参考本系列的文章 HTTP协议概述 的 Keep-Alive 机制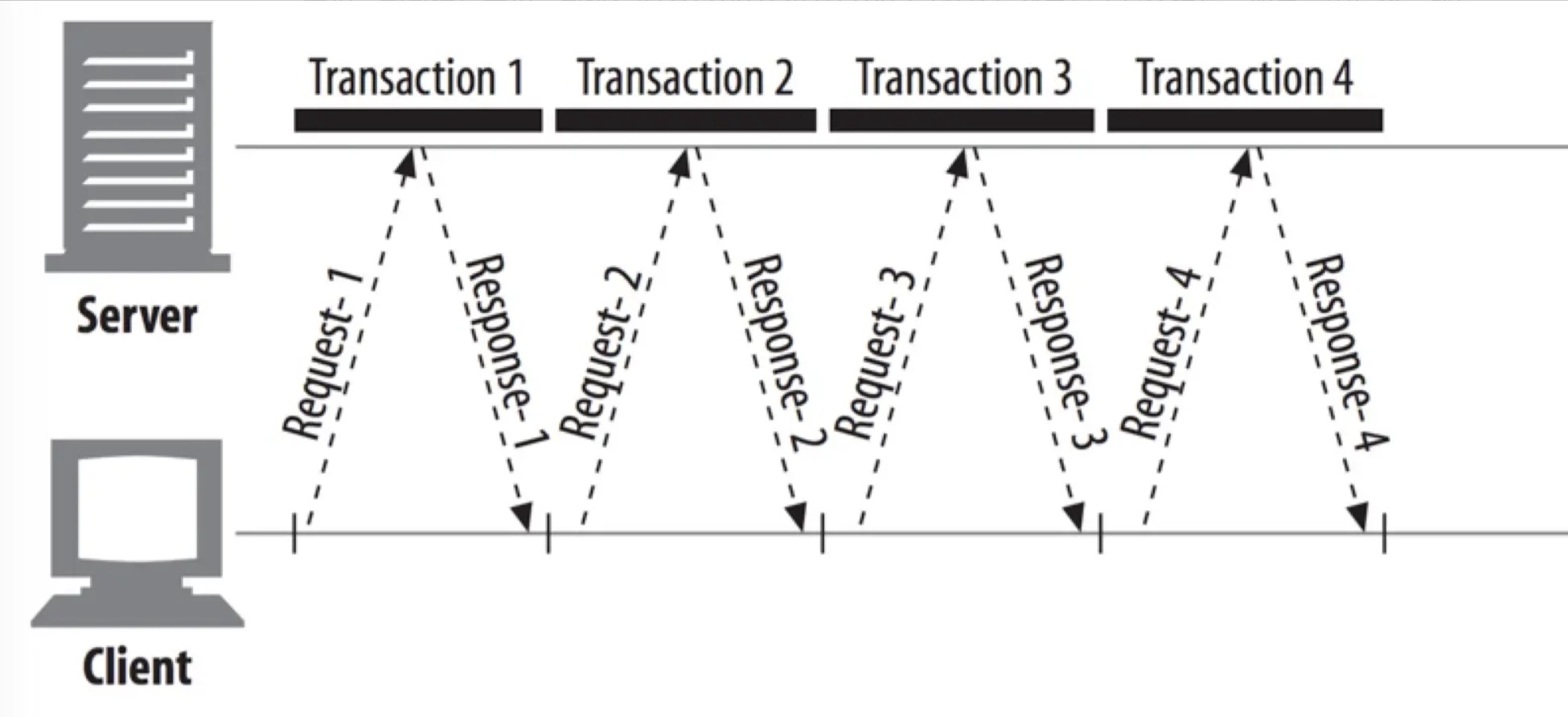
所以,我们看到,并行连接和持久连接这两种优化是相辅相成的,并行连接使得首次加载页面可以同时打开多个 TCP 连接,而持久连接保证了后续的请求复用已打开的 TCP 连接,这也是现代 Web 页面的普遍机制。
需要注意的是:不管是 http 短连接还是长连接,它们的请求和响应都有有序的,都是等上一次请求响应后,才接着下一个请求的,那能不能不等第一次请求回来,我就开始发第二次请求呢?这就引出 http 管道化连接
http1.1 pipline 管道连接
HTTP 管道允许客户端在同一个 TCP 通道内连续发起多个请求,而不必等待前一个请求的响应,消除了往返延迟时间差;但是实际情况是由于 http1.x 的限制,不允许数据在返回通道中交错返回,也就是说必须顺序返回,否则无法识别出对应标示,会显示错乱。那么这种情况下,例如,我们发送了 4 个请求,其中三个请求的 css 资源很快反回,但其中一个 html 资源服务端处理很慢会导致在 html 后面的 css 资源必须先等待 html 资源返回才能正常返回,严重时会造成缓冲区溢出,这个就是典型的 队首阻塞 问题。正是因为这个问题,所以 pipline 管道技术并没有大面积的推广和使用。
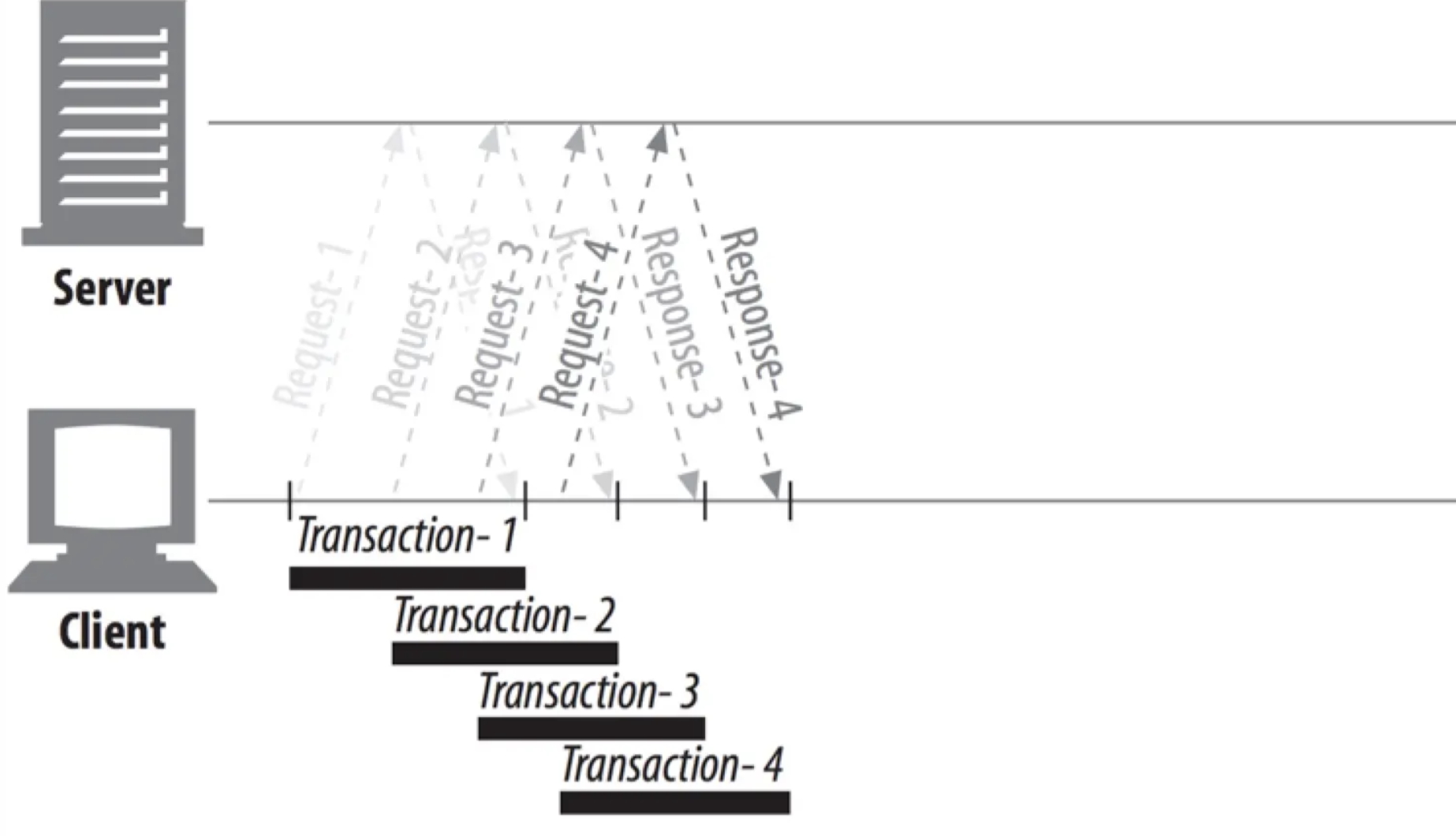
注意:队首阻塞问题在 http2.0 中得到了解决,在 http2.0 中在详细介绍