Nginx 系列(一):工作原理
Nginx 作为高性能的 HTTP 和 反向代理服务器,被广泛使用在互联网的业务中。经典的比如 Nginx + PHP-FPM 的组合。本篇文章来简单了解一下 Nginx 的基本原理。
Nginx 系列(二):源码分析
Mysql 部署系列 - 主从同步
Mysql 索引系列(五):覆盖索引
覆盖索引并不是一种索引类型,也不是索引结构,只能算是一种索引策略。
什么是覆盖索引
覆盖索引:SQL只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。
首先要了解覆盖索引之前,你必须要了解什么是聚簇索引和非聚簇索引,还有一个必须要了解的就是回表,覆盖索引其实就是跟到底需不需要回表有直接的关系的。
什么是回表呢?
通俗的讲就是,如果索引的列在 select 所需获得的列中或者根据一次索引查询就能获得记录就不需要回表,如果 select 所需获得列中有大量的非索引列,索引就需要到表中找到相应的列的信息,这就叫回表。只有非聚簇索引是需要回表的,所以如果你懂得非聚簇索引的存储的结构,你自然就知道为啥需要回表了。
为什么需要覆盖索引
举例我们建了一张学生表,其中包含字段id设置主键索引、name设置普通索引、age(无处理),并向数据库中插入 4 条数据:
- (”小赵”, 10)
- (”小王”, 11)
- (”小李”, 12)
- (”小陈”, 13)
1 | CREATE TABLE `student` ( |
这里我们设置了主键为自增,那么此时数据库里数据为:
| id | name | age |
|---|---|---|
| 1 | 小赵 | 10 |
| 2 | 小王 | 11 |
| 3 | 小李 | 12 |
| 4 | 小陈 | 13 |
每一个索引在 InnoDB 里面对应一棵B+树,那么此时就存着两棵B+树。
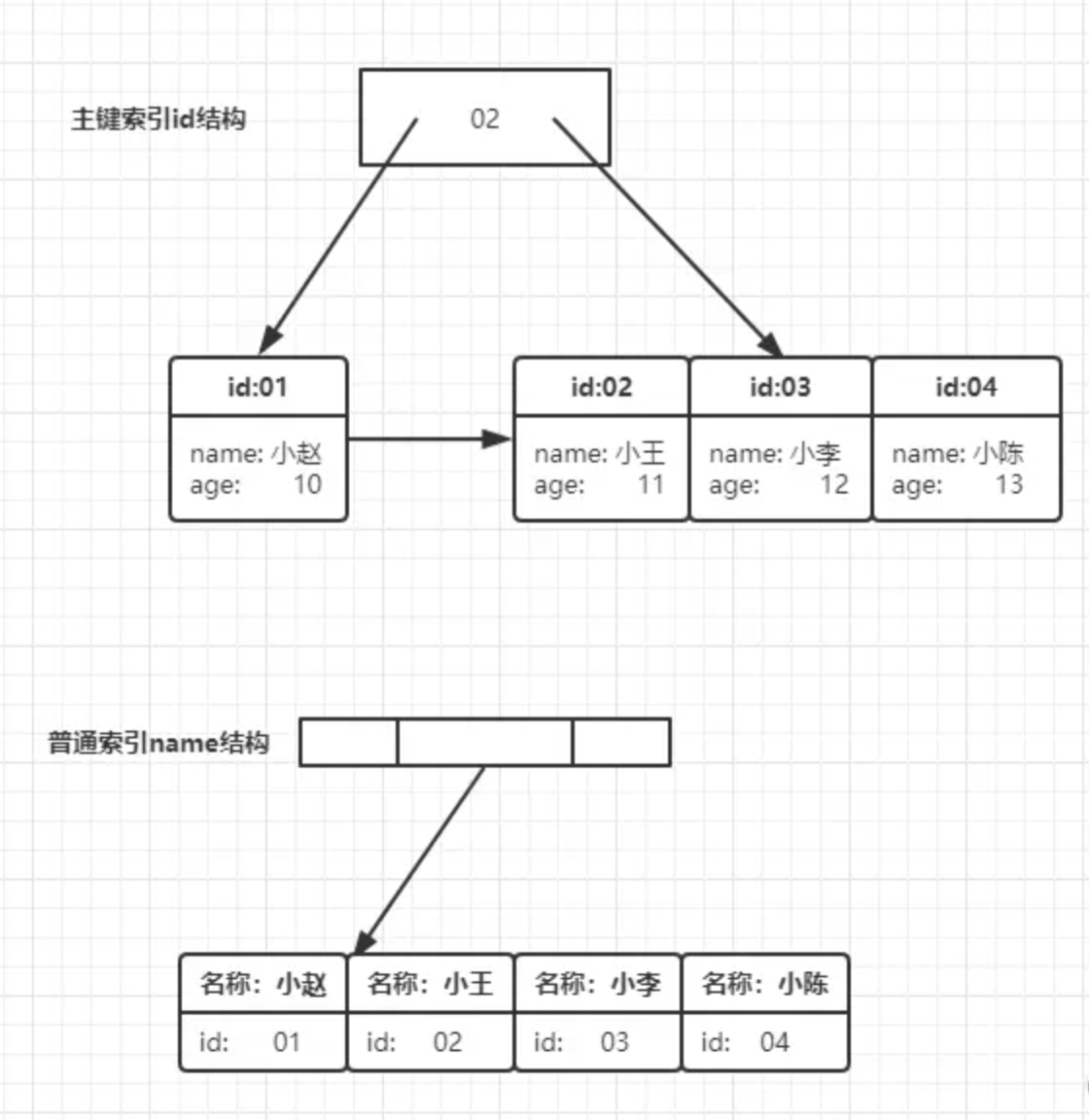
可以发现区别在与叶子节点中,主键索引存储了整行数据,而非主键索引中存储的值为主键id, 在我们执行如下sql后:
SELECT age FROM student WHERE name = ‘小李’;
流程为:
- 在 name 索引树上找到名称为小李的节点 id 为03
- 从 id 索引树上找到id为 03 的节点 获取所有数据
- 从数据中获取字段命为 age 的值返回 12
在流程中从非主键索引树搜索回到主键索引树搜索的过程称为:回表,在本次查询中因为查询结果只存在主键索引树中,我们必须回表才能查询到结果;
如何优化,不需要回表呢?
以name和age两个字段建立联合索引,sql命令与建立后的索引树结构如下:
ALTER TABLE student ADD INDEX I_name_age(name, age);
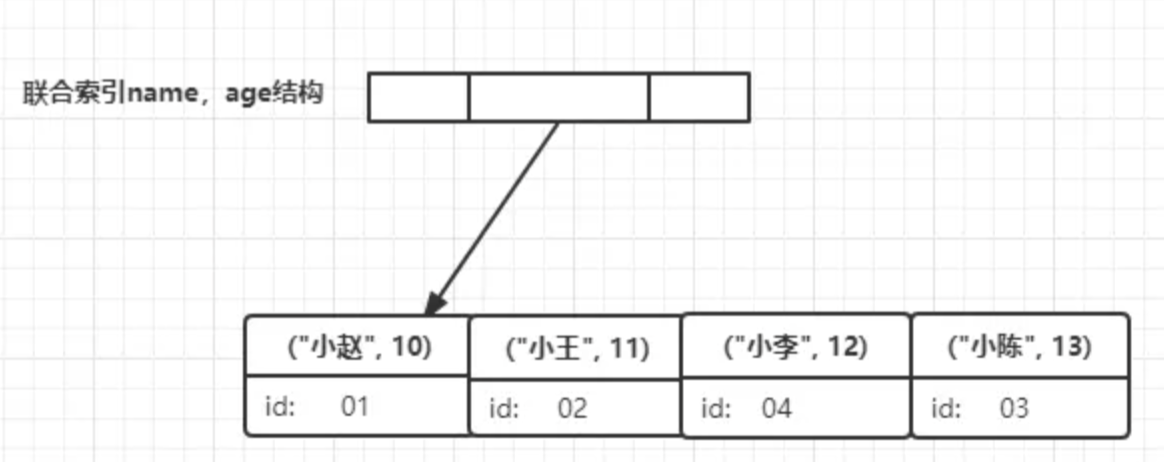
那在我们再次执行如下sql后:
SELECT age FROM student WHERE name = ‘小李’;
流程为:
- 在name,age联合索引树上找到名称为小李的节点
- 此时节点索引里包含信息age 直接返回 12
此时不再需要回表
总结
覆盖索引即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。覆盖索引并不是一种索引类型,而是一种建索引的策略。
参考资料
Mysql 索引系列(四):前缀索引
什么是前缀索引?
前缀索引也叫局部索引,比如给身份证的前 10 位添加索引,类似这种给某列部分信息添加索引的方式叫做前缀索引。
为什么要使用前缀索引?
前缀索引能有效减小索引文件的大小,让每个索引页可以保存更多的索引值,从而提高了索引查询的速度。但前缀索引也有它的缺点,不能在 order by 或者 group by 中触发前缀索引,也不能把它们用于覆盖索引。
什么情况下适合使用前缀索引?
当字符串本身可能比较长,而且前几个字符就开始不相同,适合使用前缀索引;
举例:如果有一个字段是一串 md5 加密后的字符串,那么就适合建前缀索引。
如何选择前缀索引的长度?
建立前缀索引的语法为:
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
建立索引之前,我们要关注字段的区分度,区分度越大,性能越高,意味着重复的值就越少。
这里最关键的参数就是 prefix_length,这个值需要根据实际表的内容,得到合适的索引选择性(Index Selectivity)。索引选择性就是不重复的个数与总个数的比值。
1 | select 1.0*count(distinct column_name)/count(*) |
比如我们现在有个Employee表,其中有个FirstName字段,是varchar(50)的,我们查询该字段的索引选择性:
1 | select 1.0*count(distinct FirstName)/count(*) |
得到结果0.7500,然后我们希望对FirstName建立前缀索引,希望前缀索引的选择性能够尽量贴近于对整个字段建立索引时的选择性。我们先看看3个字符,如何:
1 | select 1.0*count(distinct left(FirstName,3))/count(*) |
得到的结果是0.58784,好像差距有点大,我们再试一试4个字符呢:
1 | select 1.0*count(distinct left(FirstName,4))/count(*) |
得到0.68919,已经提升了很多,再试一试5个字符,得到的结果是0.72297,这个结果与0.75已经很接近了,所以我们这里认为前缀长度5是一个合适的取值。所以我们可以为FirstName建立前缀索引:
1 | alter table test.Employee add key(FirstName(5)) |
建立前缀索引后查询语句并不需要更改,如果我们要查询所有FirstName为Devin的Employee,那么SQL仍然写成:1
2
3select *
from Employee e
where e.FirstName='Devin';
参考资料
Mysql 索引系列(三):索引的策略
Mysql 的索引使用的是 B Tree 索引,B Tree 索引适用于全健值、键值范围、键前缀查询。所以在创建索引的时候,我们必须了解存储引擎的索引的策略。这样才能使得查询效率尽量达到最优。
本示例中使用的 Mysql 版本是: 5.7.23
Mysql 索引系列(二):了解并使用 EXPLAIN 命令
上一篇文章讲解了 Mysql 在不同的存储引擎下索引的实现,在开始讲解索引的策略以及如何优化索引之
前,我觉得有必要先来了解以下如何去使用 EXPLAIN 命令来查看sql 语句的查询方式,因为在后续的
文章中,我们会经常使用该命令来调试和分析。除此之外,我们在工作中,也应该习惯去使用 EXPLAIN
命令来分析和优化索引。
本示例中使用的 Mysql 版本是: 5.7.23
Mysql 索引系列(一):索引的实现
Mysql 数据库是目前最流行使用最广泛的关系型数据库,通过本系列来复习一下 Mysql 索引相关的知识。
本篇文章来讲解一下索引的具体实现。